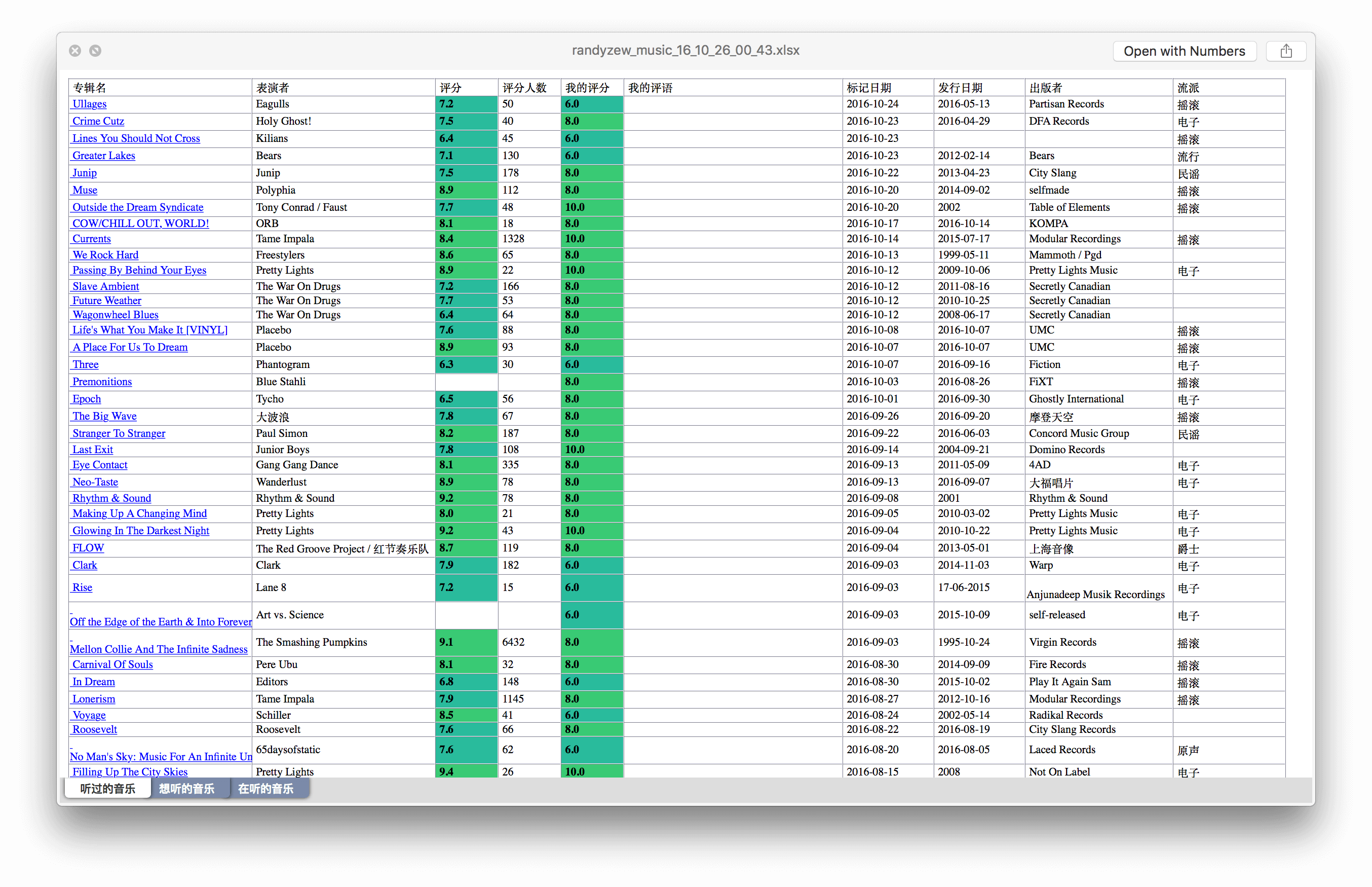
豆瓣的搜索功能实在是太弱了,想在曾经标记过的一大堆东西里找到一个条目只能靠一页一页的翻,想统计个数据更是基本不可能的事,搜索了下网上唯一一个可以导出豆瓣数据的脚本已经是 2014 年的了,早就不能用了,顺便发现有这个需求的人挺多的,不管是数据统计还是备份用途,于是我写了一个可以导出豆瓣数据的线上服务,戳链接即可:http://wil.dog/douban,可以导出如下图格式的 Excel 文件,然后按惯例记录一下开发途中遇到的问题。
爬爬爬…爬数据
爬数据的过程因为比较简单只有两层:从用户条目列表爬到所有条目的 URL,然后再从这些 URL 爬具体的条目信息,我就懒得用爬虫框架了,一边爬一边用 bs4 抓需要的信息,利用 Python 标准库带的同步队列类 Queue 实现了一个多线程的管线化工作流程。顺便吐槽下豆瓣的前端写得真的很乱,看着页面结构很相似的电影、音乐、图书页面抓信息的时候都得使用不同的方法。
403 Forbidden, 403 Forbidden, 403 Forbidden…
这才是问题的重点,在本机上爬数据不伪装请求的情况下,过一会就被豆瓣 ban 掉了,收到的回应只有 403,于是开始研究怎么伪装请求。一开始想到的是 User-Agent 和 Referer 的问题,然而加上后并没有什么卵用,然后是自然就是 Cookie 的问题了。先把浏览器访问豆瓣得到的 Cookie 带到请求里,然后正常了运行了…两分钟后,开始收到 302 回应重定向到豆瓣的机器人验证页面,要求输入验证码,然而我不想做处理验证码这么麻烦的事情,当然也更不想做用代理这种麻烦的事情,于是开始着手研究 Cookie,然而并没有发现什么规律…可能就是真的没有什么规律!Cookie 里的 bid 字段看上去是唯一管用的东西,然后就试着随机生成了一大堆 bid,每个请求再从这一堆 bid 里随机选择一个带进 Cookie 里,最后数据总算是可以正常爬而且不被 ban 了。
完全不够优雅的架构
服务器端程序是用 Flask 写的,用 uWSGI + Nginx 部署在阿里云上,然而我并没有一个通过备案的域名所以不能解析到阿里云的 80 端口上,所以只能另辟蹊径…最后的决定是前端以纯静态页面的形式托管在 Github Page 上,用 JSONP 协议和阿里云上的服务器端程序进行跨域通信。
服务器端的接口很简单只有三个,/addTask, /getState, /getFile, 分别用来请求添加新的导出任务、请求某个用户的任务状态和请求导出的 Excel 文件,前两个接口都以 JSONP 的格式返回状态内容、状态类型和可选的导出文件的 URL,前端页面在提交 /addTask 请求后会以 ajax 的方式轮训 /getState 获取并显示最新的任务状态直到任务成功或失败。
考虑到效率和避免滥用问题,导出的文件会在服务器暂存 24 小时,24 小时内请求添加同样的导出任务都会直接返回暂存的文件,与此同时我把最大并发任务数限制到了 6 个,超过之后请求添加新的导出任务会提示排队,测试了一下 6 个并发任务基本上就是我这个 1G RAM 单核 CPU 阿里云的极限了…
前端页面和服务器端源码都放 Github 上了,和部署时用的程序有少量区别,由兴趣的可以给个 star:https://github.com/Wildog/douban-exporter
Published:
